
Industry (public)
1. GPT3 blog generation tool for Satya’s demo at Microsoft Ignite
link
keywords : Large Language models, GPT3, NLP, Deep Learning
Built POC for real-time transcription, correction, summarization and creative blog writing for WNBA games in low domain specific data settings.
2. Interpret Text - Open-source tool for State-of-the-Art text-based Model Explanations
link
keywords : Explainability, NLP, Deep Learning
Implemented & architected one of the first general purpose toolkits for architecture agnostic interpretation of contemporary & classical NLP models.
3. Adding support for XLNET in MSFT’s core NLP repository
link
keywords : Deep Learning, NLP, Tranformers
4. Implementing Deeplab v3+ in Production for Matlab.
link ; Feature page
keywords : Computer Vision, Deep Learning
Academia
1. Stagewise non-uniform regularization for Cascade classifiers
link
keywords : ML for Healthcare, ML on edge/IOT devices
We propose a new approach to building cascaded classifiers in computation sensitive, low power environments. We extend the firm cascade architecture by introducing non-uniform stage-wise regression terms into the loss function. We introduce a modification over the L1 regularizer, tuned to encourage sparse connections. We evaluate the effects of such a regularizer on use cases with imbalanced classes such as human activity recognition and smoking detection.

2. Hand-drawn images to Simulink programs
keywords : Computer Vision, Deep Learning
We convert rough hand drawn images of full simulink diagrams and convert them to full working Simulink models in machine. I worked on the exraction, detection and classification part of the pipeline.
We made a custom dataset, finetuned an imagenet pretrained GoogLeNet based model and used classical vision, topological, density and connectivity properties to extract the graphical structure and flow from the image.
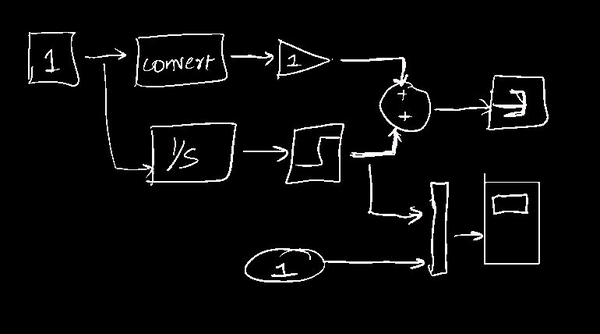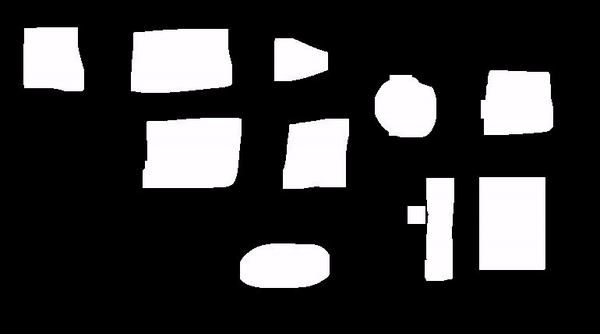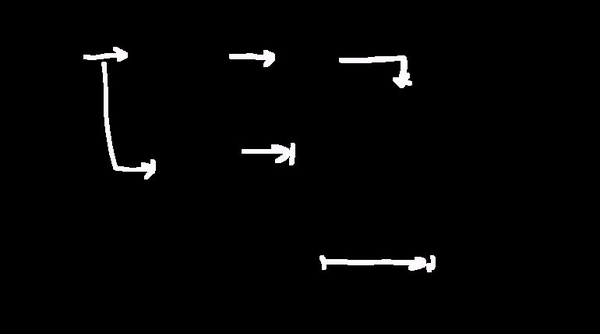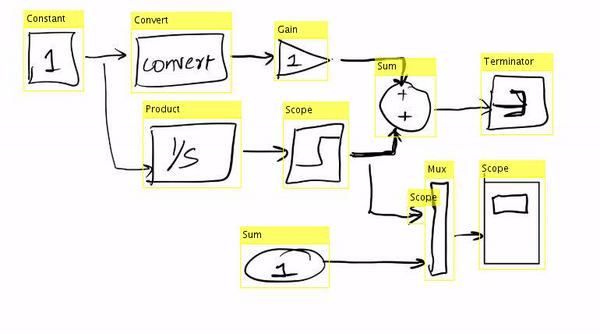
3. Convert Audio files to Video of person speaking
keywords : Deeplearning, Vision, Multi-modal ML
We use an LSTM to take an audio file as input and generate a video of a person speaking in sync with the audio file. The goal is to preserve facial landmarks. The base face model is input as the initial state of the LSTM and the audio signal for a particular time interval is fed at each timestep.
4. Exploring Sophisticated Loss Functions for Early Prediction in CNNS:
link
keywords : Deeplearning, Vision, Compute-aware ML
We investigate the effects of using sophisticated cascade loss functions on early predictions in image classification tasks. We apply methods native to cascade classifiers, to guide the learning of Convolutional Neural Networks. We approach the problem by trying to identify the depth and if to place an intermediate classifier in a CNN pipeline, so as to achieve a better accuracy-cost trade-off. We use a modified AlexNet as the base model. We also extend the soft cascade and firm cascade loss functions to the multi-label case using each for training the model.
5. Predicting Neighborhoods most affected by Crime using Infrastructure and Economic Indicators:
link
keywords : Computational Social Science, Dataset creation
We propose a novel approach to predict crime for neighborhoods in a city from multiple sources, in particular nearby landmarks, census and demographic data. Many prior studies have tried to predict crime based on demographic and socio-economic data, but there has been no prior work on prediction of crime based on landmarks data. We were able to successfully show that local infrastructure data plays a more important role in predicting crime incidents. We also showed the importance of different features on crime rate. We were able to confirm the results of prior studies related to correlation between crime, and schools and banks.
6. Design and Fabrication of SLAM based, autonomous material handling robot
link
keywords : Vision, Robotics
